There is an excellent article on "Fast String Searching" by John W. Ross in the "C/C++ Users Journal" of July 1995. A paper copy of the article will be put on library reserve for photocopying.
The code provided in the article has been typed in and is available through the links below. You can easily see how the routines work and make use of these programs.
Links to source code files
- Main program for timing and testing
- Brute force string searching
- Improve by first character search:
look for a match of 1st pattern character before checking rest of pattern - Call C library string match function
- Improve by low frequency character search:
look for a match of the lowest freq. char. in pattern before checking rest of pattern - Boyer-Moore-Horspool function
- Main program for Boyer-Moore-Horspool function
 )
)
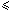 i < m and x[m-1-i]=c}
i < m and x[m-1-i]=c}