List search algorithms are perhaps the most basic kind of search algorithm. The goal is to find one element of a set by some key (perhaps containing other information related to the key). As this is a common problem in computer science, the computational complexity of these algorithms has been well studied. The simplest such algorithm is linear search, which simply examines each element of the list in order. It has expensive O(n) running time, where n is the number of items in the list, but can be used directly on any unprocessed list. A more sophisticated list search algorithm is binary search; it runs in O(log n) time. This is significantly better than linear search for large lists of data, but it requires that the list be sorted before searching (see sorting algorithm) and also be random access. Interpolation search is better than binary search for large sorted lists with fairly even distributions, but has a worst-case running time of O(n).
Grover's algorithm is a quantum algorithm that offers quadratic speedup over the classical linear search for unsorted lists. However, it requires a currently non-existent quantum computer on which to run.
Hash tables are also used for list search, requiring only constant time for search in the average case, but more space overhead and terrible O(n) worst-case search time. Another search based on specialized data structures uses self-balancing binary search trees and requires O(log n) time to search; these can be seen as extending the main ideas of binary search to allow fast insertion and removal. See associative array for more discussion of list search data structures.
Most list search algorithms, such as linear search, binary search, and self-balancing binary search trees, can be extended with little additional cost to find all values less than or greater than a given key, an operation called range search. The glaring exception is hash tables, which cannot perform such a search efficiently.
 )
)
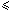 i < m and x[m-1-i]=c}
i < m and x[m-1-i]=c}